|
|
@@ -2,49 +2,900 @@
|
|
|
|
|
|
\section{Memory/bandwidth optimization}
|
|
|
|
|
|
+ % 1) (malloc, first-touch, bandwidth, free) for (writing to array)
|
|
|
+ % 2) (bandwidth) for (reading array) [reduction]
|
|
|
+ % 3) (flop,bandwidth) for (vector copy, vector-add) (write causes read -- unless streaming write)
|
|
|
+ % 4) (latency) for (sequential access, strided access) (integer array with indices)
|
|
|
+ % x2 - single and multi threaded
|
|
|
+
|
|
|
+ % plot: X (size), Y (cycles) ---- vary stride length
|
|
|
+
|
|
|
+ % spatial and temporal data locality
|
|
|
+
|
|
|
+ % hyper threading - shared cache - useful for latency bound
|
|
|
+
|
|
|
\begin{frame} \frametitle{Memory}{} %<<<
|
|
|
\begin{columns}
|
|
|
\column{0.5\textwidth}
|
|
|
- \begin{itemize}
|
|
|
- \item How does memory work?
|
|
|
- \end{itemize}
|
|
|
|
|
|
- Ulrich Drepper -- What every programmer should know about memory (2007)
|
|
|
- %https://lwn.net/Articles/252125/
|
|
|
+ How does computer memory work?
|
|
|
+
|
|
|
+ \vspace{2em}
|
|
|
+ References:
|
|
|
+ {\small
|
|
|
+ \begin{itemize}
|
|
|
+ \setlength\itemsep{1em}
|
|
|
+ \item Ulrich Drepper -- What every programmer should know about memory (2007)
|
|
|
+ %https://lwn.net/Articles/252125/
|
|
|
+
|
|
|
+ \item Igor Ostrovsky -- Gallery of Processor Cache Effects %\url{http://igoro.com/archive/gallery-of-processor-cache-effects}
|
|
|
+ \end{itemize}
|
|
|
+ }
|
|
|
|
|
|
\column{0.5\textwidth}
|
|
|
- \center
|
|
|
- \includegraphics[width=0.99\textwidth]{figs/cache-hierarchy}
|
|
|
+ \center
|
|
|
+ \includegraphics[width=0.99\textwidth]{figs/cache-hierarchy}
|
|
|
|
|
|
- {\footnotesize Source: Intel Software Developer Manual}
|
|
|
+ {\footnotesize Source: Intel Software Developer Manual}
|
|
|
\end{columns}
|
|
|
\end{frame}
|
|
|
%>>>
|
|
|
|
|
|
+\begin{frame}[t,fragile] \frametitle{Memory benchmarks}{} %<<<
|
|
|
|
|
|
-\begin{frame} \frametitle{Latency and bandwidth}{} %<<<
|
|
|
+ \begin{columns}
|
|
|
+ \column{0,55\textwidth}
|
|
|
+ \footnotesize
|
|
|
+ \begin{overprint}
|
|
|
+ \onslide<1->%<<<
|
|
|
+ \begin{minted}[
|
|
|
+ frame=lines,
|
|
|
+ fontsize=\footnotesize,
|
|
|
+ linenos,
|
|
|
+ autogobble,
|
|
|
+ mathescape
|
|
|
+ ]{C++}
|
|
|
+ long N = 1e9; // 8 GB
|
|
|
|
|
|
+ // Allocate memory
|
|
|
+ double* X = (double*)malloc(N*sizeof(double));
|
|
|
|
|
|
- % 1) (malloc, first-touch, bandwidth, free) for (writing to array)
|
|
|
- % 2) (bandwidth) for (reading array) [reduction]
|
|
|
- % 3) (flop,bandwidth) for (vector copy, vector-add) (write causes read -- unless streaming write)
|
|
|
- % 4) (latency) for (sequential access, strided access) (integer array with indices)
|
|
|
- % x2 - single and multi threaded
|
|
|
+ // Initialize array
|
|
|
+ for (long i = 0; i < N; i++) X[i] = i;
|
|
|
|
|
|
+ // Write to array
|
|
|
+ for (long i = 0; i < N; i++) X[i] = 2*i;
|
|
|
|
|
|
- % plot: X (size), Y (cycles) ---- vary stride length
|
|
|
+ // Free memory
|
|
|
+ free(X);
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+ \end{overprint}
|
|
|
|
|
|
- % spatial and temporal data locality
|
|
|
+ \column{0.05\textwidth}
|
|
|
+ \column{0.4\textwidth}
|
|
|
|
|
|
- % hyper threading - shared cache - useful for latency bound
|
|
|
+ \vspace{0.3em}
|
|
|
+ \begin{overprint}
|
|
|
+ \onslide<2->%<<<
|
|
|
+ \begin{minted}[autogobble,fontsize=\footnotesize]{text}
|
|
|
+
|
|
|
+ Allocate memory
|
|
|
+ T = 1.60821e-05
|
|
|
+
|
|
|
+ Initialize array
|
|
|
+ T = 1.75352 --- 4.6 GB/s
|
|
|
+
|
|
|
+ Write to array
|
|
|
+ T = 0.84467 --- 9.5 GB/s
|
|
|
+
|
|
|
+ Free memory
|
|
|
+ T = 0.0141113
|
|
|
+ \end{minted}
|
|
|
+
|
|
|
+ %\textcolor{red}{\qquad only $1.5\times$ speedup :(}
|
|
|
+ %>>>
|
|
|
+ \end{overprint}
|
|
|
+
|
|
|
+ \end{columns}
|
|
|
+
|
|
|
+ \vspace{0.5em}
|
|
|
+ \only<3->{
|
|
|
+ \vspace{0.5em}
|
|
|
+ \begin{columns}
|
|
|
+ \column{0.6\textwidth}
|
|
|
+ \textcolor{red}{Memory allocations are not free!}
|
|
|
+ \begin{itemize}
|
|
|
+ \item \textcolor{red}{cost is hidden in initialization (first-touch)}
|
|
|
+ \end{itemize}
|
|
|
+ \end{columns}
|
|
|
+ }
|
|
|
|
|
|
\end{frame}
|
|
|
%>>>
|
|
|
|
|
|
-% Stack vs heap memory
|
|
|
-% vector vs linked list
|
|
|
+\begin{frame}[t,fragile] \frametitle{L1-cache bandwidth}{} %<<<
|
|
|
+
|
|
|
+ \begin{columns}
|
|
|
+ \column{0,55\textwidth}
|
|
|
+ \footnotesize
|
|
|
+ \begin{overprint}
|
|
|
+ \onslide<1->%<<<
|
|
|
+ \begin{minted}[
|
|
|
+ frame=lines,
|
|
|
+ fontsize=\footnotesize,
|
|
|
+ linenos,
|
|
|
+ autogobble,
|
|
|
+ mathescape
|
|
|
+ ]{C++}
|
|
|
+ long N = 2048; // 16KB
|
|
|
+ double* X = (double*)malloc(N*sizeof(double));
|
|
|
+ double* Y = (double*)malloc(N*sizeof(double));
|
|
|
+ // Initialize X, Y
|
|
|
+
|
|
|
+ // Write to array
|
|
|
+ for (long i = 0; i < N; i++) X[i] = 3.14;
|
|
|
+
|
|
|
+ // Read from array
|
|
|
+ double sum = 0;
|
|
|
+ for (long i = 0; i < N; i++) sum += X[i];
|
|
|
+
|
|
|
+ // Adding arrays: 2-reads, 1-write
|
|
|
+ for (long i = 0; i < N; i++) Y[i] += X[i];
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+ \end{overprint}
|
|
|
+
|
|
|
+ \column{0.05\textwidth}
|
|
|
+ \column{0.4\textwidth}
|
|
|
+
|
|
|
+ \vspace{0.5em}
|
|
|
+ \begin{overprint}
|
|
|
+ \onslide<2->%<<<
|
|
|
+ \begin{minted}[autogobble,fontsize=\footnotesize]{text}
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+ Writing to array
|
|
|
+ Bandwidth = 26.2744 GB/s
|
|
|
+
|
|
|
+ Reading from array
|
|
|
+ Bandwidth = 6.57305 GB/s
|
|
|
+
|
|
|
+
|
|
|
+ Adding arrays
|
|
|
+ Bandwidth = 131.203 GB/s
|
|
|
+ \end{minted}
|
|
|
+
|
|
|
+ %\textcolor{red}{\qquad only $1.5\times$ speedup :(}
|
|
|
+ %>>>
|
|
|
+ \end{overprint}
|
|
|
+
|
|
|
+ \end{columns}
|
|
|
+
|
|
|
+\end{frame}
|
|
|
+%>>>
|
|
|
+
|
|
|
+\begin{frame}[t,fragile] \frametitle{L1-cache bandwidth (vectorized)}{} %<<<
|
|
|
+
|
|
|
+ \begin{columns}
|
|
|
+ \column{0,55\textwidth}
|
|
|
+ \footnotesize
|
|
|
+ \begin{overprint}
|
|
|
+ \onslide<1-2>%<<<
|
|
|
+ \begin{minted}[
|
|
|
+ frame=lines,
|
|
|
+ fontsize=\footnotesize,
|
|
|
+ linenos,
|
|
|
+ autogobble,
|
|
|
+ mathescape
|
|
|
+ ]{C++}
|
|
|
+ using Vec = sctl::Vec<double,8>;
|
|
|
+
|
|
|
+ long N = 2048; // 16KB
|
|
|
+ double* X = (double*)malloc(N*sizeof(double));
|
|
|
+ double* Y = (double*)malloc(N*sizeof(double));
|
|
|
+ // Initialize X, Y
|
|
|
+
|
|
|
+ // Write to array
|
|
|
+ Vec v = 3.14;
|
|
|
+ #pragma GCC unroll (4)
|
|
|
+ for (long i = 0; i < N; i+=8) v.Store(X+i);
|
|
|
+
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+
|
|
|
+ \onslide<3-4>%<<<
|
|
|
+ \begin{minted}[
|
|
|
+ frame=lines,
|
|
|
+ fontsize=\footnotesize,
|
|
|
+ linenos,
|
|
|
+ autogobble,
|
|
|
+ mathescape
|
|
|
+ ]{C++}
|
|
|
+
|
|
|
+ // Read from array
|
|
|
+ Vec sum[8] = {0.,0.,0.,0.,0.,0.,0.,0.};
|
|
|
+ for (long i = 0; i < N; i+=8*8) {
|
|
|
+ sum[0] = sum[0] + Vec::Load(X +i);
|
|
|
+ sum[1] = sum[1] + Vec::Load(X+8 +i);
|
|
|
+ sum[2] = sum[2] + Vec::Load(X+16+i);
|
|
|
+ sum[3] = sum[3] + Vec::Load(X+24+i);
|
|
|
+ sum[4] = sum[4] + Vec::Load(X+32+i);
|
|
|
+ sum[5] = sum[5] + Vec::Load(X+40+i);
|
|
|
+ sum[6] = sum[6] + Vec::Load(X+48+i);
|
|
|
+ sum[7] = sum[7] + Vec::Load(X+56+i);
|
|
|
+ }
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+
|
|
|
+ \onslide<5-6>%<<<
|
|
|
+ \begin{minted}[
|
|
|
+ frame=lines,
|
|
|
+ fontsize=\footnotesize,
|
|
|
+ linenos,
|
|
|
+ autogobble,
|
|
|
+ mathescape
|
|
|
+ ]{C++}
|
|
|
+
|
|
|
+ // Adding arrays: 2-reads, 1-write
|
|
|
+ for (long i = 0; i < N; i+=8*2) {
|
|
|
+ Vec X0 = Vec::Load(X+0+i);
|
|
|
+ Vec X1 = Vec::Load(X+8+i);
|
|
|
+ Vec Y0 = Vec::Load(Y+0+i);
|
|
|
+ Vec Y1 = Vec::Load(Y+8+i);
|
|
|
+ (X0+Y0).Store(Y+VecLen*0+i);
|
|
|
+ (X1+Y1).Store(Y+VecLen*1+i);
|
|
|
+ }
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+ \end{overprint}
|
|
|
+
|
|
|
+ \column{0.05\textwidth}
|
|
|
+ \column{0.4\textwidth}
|
|
|
+
|
|
|
+ \vspace{0.5em}
|
|
|
+ \begin{overprint}
|
|
|
+ \onslide<2-3>%<<<
|
|
|
+ \begin{minted}[autogobble,fontsize=\footnotesize]{text}
|
|
|
+ Writing to array
|
|
|
+ Bandwidth = 89.5993 GB/s
|
|
|
+ cycles/iter = 2.35716
|
|
|
+
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+ \onslide<4-5>%<<<
|
|
|
+ \begin{minted}[autogobble,fontsize=\footnotesize]{text}
|
|
|
+ Writing to array
|
|
|
+ Bandwidth = 89.5993 GB/s
|
|
|
+ cycles/iter = 2.35716
|
|
|
+
|
|
|
+ Reading from array
|
|
|
+ Bandwidth = 210.375 GB/s
|
|
|
+ cycles/iter = 1.00392
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+ \onslide<6->%<<<
|
|
|
+ \begin{minted}[autogobble,fontsize=\footnotesize]{text}
|
|
|
+ Writing to array
|
|
|
+ Bandwidth = 89.5993 GB/s
|
|
|
+ cycles/iter = 2.35716
|
|
|
+
|
|
|
+ Reading from array
|
|
|
+ Bandwidth = 210.375 GB/s
|
|
|
+ cycles/iter = 1.00392
|
|
|
+
|
|
|
+ Adding arrays
|
|
|
+ Bandwidth = 148.29 GB/s
|
|
|
+ cycles/iter = 4.27271
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+ \end{overprint}
|
|
|
+
|
|
|
+ \end{columns}
|
|
|
+
|
|
|
+\end{frame}
|
|
|
+%>>>
|
|
|
+
|
|
|
+\begin{frame}[t,fragile] \frametitle{L1-cache bandwidth (vectorized \& aligned)}{} %<<<
|
|
|
+
|
|
|
+ \begin{columns}
|
|
|
+ \column{0,55\textwidth}
|
|
|
+ \begin{overprint}
|
|
|
+ \onslide<1>%<<<
|
|
|
+ \vspace{0.5em}
|
|
|
+ Unaligned read:\\
|
|
|
+ \resizebox{0.8\textwidth}{!}{\begin{tikzpicture} %<<<
|
|
|
+ \fill[c3] (0.75,1) rectangle (2.75,1.25);
|
|
|
+ \draw[step=0.25,thick, darkgray] (0.749,0.99) grid (2.75,1.25);
|
|
|
+ \node at (3.3,1.125) {\footnotesize register};
|
|
|
+
|
|
|
+ \fill[c2] (0,0) rectangle (2,-0.25);
|
|
|
+ \draw[step=0.25,thick, darkgray] (0,0) grid (2,-0.25);
|
|
|
+
|
|
|
+ \fill[c2] (2.25,0) rectangle (4.25,-0.25);
|
|
|
+ \draw[step=0.25,thick, darkgray] (2.249,0) grid (4.25,-0.25);
|
|
|
+ \node at (2.1,-0.4) {\footnotesize L1 cache};
|
|
|
+
|
|
|
+ \draw[-latex, thick] (0.875,0.1) -- (0.875,0.9);
|
|
|
+ \draw[-latex, thick] (1.125,0.1) -- (1.125,0.9);
|
|
|
+ \draw[-latex, thick] (1.375,0.1) -- (1.375,0.9);
|
|
|
+ \draw[-latex, thick] (1.625,0.1) -- (1.625,0.9);
|
|
|
+ \draw[-latex, thick] (1.875,0.1) -- (1.875,0.9);
|
|
|
+
|
|
|
+ \draw[-latex, thick] (2.375,0.1) -- (2.125,0.9);
|
|
|
+ \draw[-latex, thick] (2.625,0.1) -- (2.375,0.9);
|
|
|
+ \draw[-latex, thick] (2.875,0.1) -- (2.625,0.9);
|
|
|
+ \end{tikzpicture}}%>>>
|
|
|
+ %>>>
|
|
|
+
|
|
|
+ \onslide<2->%<<<
|
|
|
+ \vspace{0.5em}
|
|
|
+ Aligned read:\\
|
|
|
+ \resizebox{0.8\textwidth}{!}{\begin{tikzpicture} %<<<
|
|
|
+ \fill[c3] (0,1) rectangle (2,1.25);
|
|
|
+ \draw[step=0.25,thick, darkgray] (0,0.99) grid (2,1.25);
|
|
|
+ \node at (2.55,1.125) {\footnotesize register};
|
|
|
+
|
|
|
+ \fill[c2] (0,0) rectangle (2,-0.25);
|
|
|
+ \draw[step=0.25,thick, darkgray] (0,0) grid (2,-0.25);
|
|
|
+
|
|
|
+ \fill[c2] (2.25,0) rectangle (4.25,-0.25);
|
|
|
+ \draw[step=0.25,thick, darkgray] (2.249,0) grid (4.25,-0.25);
|
|
|
+ \node at (2.1,-0.4) {\footnotesize L1 cache};
|
|
|
+
|
|
|
+ \draw[-latex, thick] (0.125,0.1) -- (0.125,0.9);
|
|
|
+ \draw[-latex, thick] (0.375,0.1) -- (0.375,0.9);
|
|
|
+ \draw[-latex, thick] (0.625,0.1) -- (0.625,0.9);
|
|
|
+ \draw[-latex, thick] (0.875,0.1) -- (0.875,0.9);
|
|
|
+ \draw[-latex, thick] (1.125,0.1) -- (1.125,0.9);
|
|
|
+ \draw[-latex, thick] (1.375,0.1) -- (1.375,0.9);
|
|
|
+ \draw[-latex, thick] (1.625,0.1) -- (1.625,0.9);
|
|
|
+ \draw[-latex, thick] (1.875,0.1) -- (1.875,0.9);
|
|
|
+ \end{tikzpicture}}%>>>
|
|
|
+
|
|
|
+ \vspace{0.2em}
|
|
|
+ \small
|
|
|
+ Replace:
|
|
|
+ \begin{itemize}
|
|
|
+ \item malloc $\rightarrow$ sctl::aligned\_new
|
|
|
+ \item Vec::Load $\rightarrow$ Vec::AlignedLoad
|
|
|
+ \item Vec::Store $\rightarrow$ Vec::AlignedStore
|
|
|
+ \end{itemize}
|
|
|
+ %>>>
|
|
|
+ \end{overprint}
|
|
|
+
|
|
|
+ \column{0.05\textwidth}
|
|
|
+ \column{0.4\textwidth}
|
|
|
+ \begin{overprint}
|
|
|
+ \onslide<3->%<<<
|
|
|
+ \begin{minted}[autogobble,fontsize=\footnotesize]{text}
|
|
|
+ Writing to array
|
|
|
+ Bandwidth = 210.273 GB/s
|
|
|
+ cycles/iter = 1.00441
|
|
|
+
|
|
|
+ Reading from array
|
|
|
+ Bandwidth = 380.953 GB/s
|
|
|
+ cycles/iter = 0.554399
|
|
|
+
|
|
|
+ Adding arrays
|
|
|
+ Bandwidth = 325.592 GB/s
|
|
|
+ cycles/iter = 1.94599
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+ \end{overprint}
|
|
|
+
|
|
|
+ \end{columns}
|
|
|
+
|
|
|
+ \vspace{1em}
|
|
|
+ \begin{columns}
|
|
|
+ \column{0.65\textwidth}
|
|
|
+ \only<3>{\textcolor{red}{Aligned memory acceses to L1 can be $2\times$ faster!}}
|
|
|
+ \end{columns}
|
|
|
+
|
|
|
+\end{frame}
|
|
|
+%>>>
|
|
|
+
|
|
|
+\begin{frame}[t,fragile] \frametitle{Main memory bandwidth}{} %<<<
|
|
|
+
|
|
|
+ \begin{columns}
|
|
|
+ \column{0,6\textwidth}
|
|
|
+ \footnotesize
|
|
|
+ \begin{overprint}
|
|
|
+ \onslide<1->%<<<
|
|
|
+ \begin{minted}[
|
|
|
+ frame=lines,
|
|
|
+ fontsize=\footnotesize,
|
|
|
+ linenos,
|
|
|
+ autogobble,
|
|
|
+ mathescape
|
|
|
+ ]{C++}
|
|
|
+ long N = 1e9; // 8 GB
|
|
|
+
|
|
|
+ // Initialize X, Y
|
|
|
+ for (long i = 0; i < N; i++) X[i] = Y[i] = i;
|
|
|
+
|
|
|
+ // Write to array
|
|
|
+ #pragma omp parallel for schedule(static)
|
|
|
+ for (long i = 0; i < N; i++) X[i] = 3.14;
|
|
|
+
|
|
|
+ // Read from array
|
|
|
+ double sum = 0;
|
|
|
+ #pragma omp parallel for schedule(static) reduction(+:sum)
|
|
|
+ for (long i = 0; i < N; i++) sum += X[i];
|
|
|
+
|
|
|
+ // Adding arrays: 2-reads, 1-write
|
|
|
+ #pragma omp parallel for schedule(static)
|
|
|
+ for (long i = 0; i < N; i++) Y[i] += X[i];
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+ \end{overprint}
|
|
|
+
|
|
|
+ \column{0.05\textwidth}
|
|
|
+ \column{0.35\textwidth}
|
|
|
|
|
|
-\begin{frame} \frametitle{Shared memory pitfalls}{} %<<<
|
|
|
+ \vspace{0.5em}
|
|
|
+ \begin{overprint}
|
|
|
+ \onslide<2->%<<<
|
|
|
+ \begin{minted}[autogobble,fontsize=\footnotesize]{text}
|
|
|
+
|
|
|
+
|
|
|
+ Writing to array
|
|
|
+ Bandwidth = 35.4136 GB/s
|
|
|
+
|
|
|
+
|
|
|
+ Reading from array
|
|
|
+ Bandwidth = 69.4623 GB/s
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+ Adding arrays
|
|
|
+ Bandwidth = 113.637 GB/s
|
|
|
+ \end{minted}
|
|
|
+
|
|
|
+ %\textcolor{red}{\qquad only $1.5\times$ speedup :(}
|
|
|
+ %>>>
|
|
|
+ \end{overprint}
|
|
|
+
|
|
|
+ \end{columns}
|
|
|
+
|
|
|
+\end{frame}
|
|
|
+%>>>
|
|
|
+
|
|
|
+\begin{frame} \frametitle{Non-uniform Memory Access}{} %<<<
|
|
|
+
|
|
|
+ \begin{itemize}
|
|
|
+ %\item {\bf Cores:} individual processing units.
|
|
|
+ %\item {\bf Sockets:} collection of cores on the same silicon die.
|
|
|
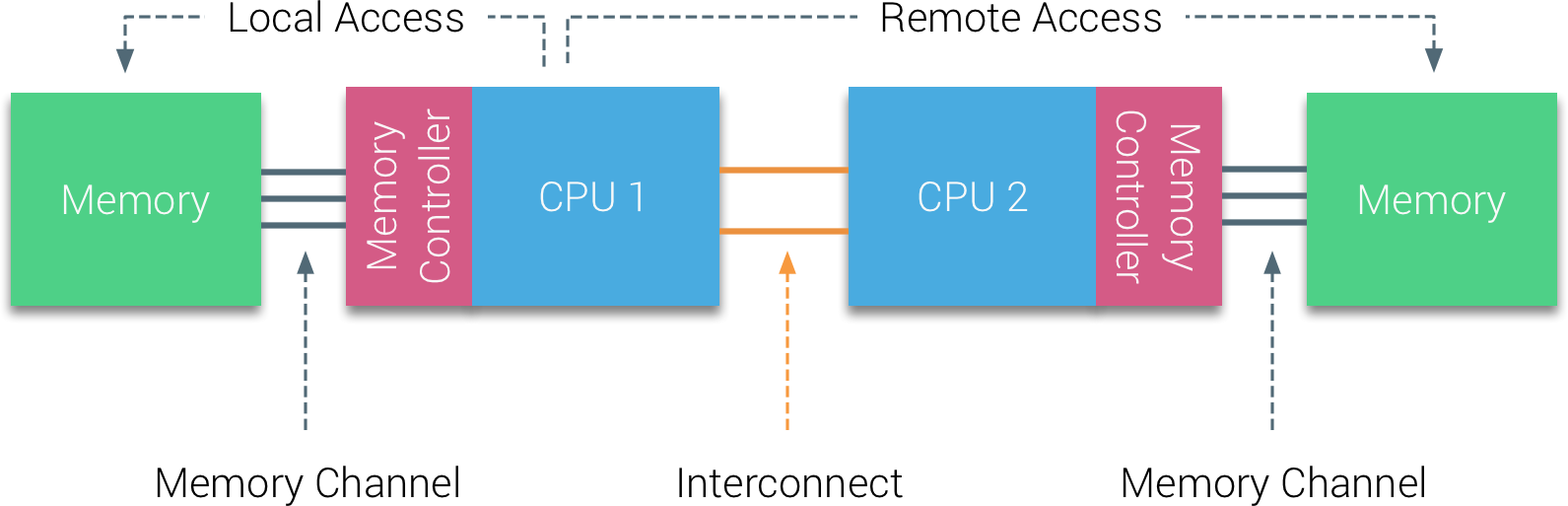
+ \item Each sockets connected to its own DRAM.
|
|
|
+ \item Sockets interconnected using a network: QPI (Intel), HT (AMD).
|
|
|
+ \item Location of memory pages determined by first-touch policy.
|
|
|
+ \end{itemize}
|
|
|
+
|
|
|
+ \center
|
|
|
+ \includegraphics[width=0.7\textwidth]{figs/numa1}
|
|
|
+
|
|
|
+ {\scriptsize Source: \url{https://frankdenneman.nl/2016/07/07/numa-deep-dive-part-1-uma-numa}}
|
|
|
+\end{frame}
|
|
|
+%>>>
|
|
|
+
|
|
|
+\begin{frame}[t,fragile] \frametitle{Main memory bandwidth (NUMA aware)}{} %<<<
|
|
|
+
|
|
|
+ \begin{columns}
|
|
|
+ \column{0,6\textwidth}
|
|
|
+ \footnotesize
|
|
|
+ \begin{overprint}
|
|
|
+ \onslide<1-2>%<<<
|
|
|
+ \begin{minted}[
|
|
|
+ frame=lines,
|
|
|
+ fontsize=\footnotesize,
|
|
|
+ linenos,
|
|
|
+ autogobble,
|
|
|
+ mathescape
|
|
|
+ ]{C++}
|
|
|
+ long N = 1e9; // 8 GB
|
|
|
+
|
|
|
+ // Initialize X, Y
|
|
|
+ #pragma omp parallel for schedule(static)
|
|
|
+ for (long i = 0; i < N; i++) X[i] = Y[i] = i;
|
|
|
+
|
|
|
+ // Write to array
|
|
|
+ #pragma omp parallel for schedule(static)
|
|
|
+ for (long i = 0; i < N; i++) X[i] = 3.14;
|
|
|
+
|
|
|
+ // Read from array
|
|
|
+ double sum = 0;
|
|
|
+ #pragma omp parallel for schedule(static) reduction(+:sum)
|
|
|
+ for (long i = 0; i < N; i++) sum += X[i];
|
|
|
+
|
|
|
+ // Adding arrays: 2-reads, 1-write
|
|
|
+ #pragma omp parallel for schedule(static)
|
|
|
+ for (long i = 0; i < N; i++) Y[i] += X[i];
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+ \onslide<3>%<<<
|
|
|
+ \begin{minted}[autogobble,fontsize=\footnotesize]{text}
|
|
|
+ \end{minted}
|
|
|
+ \center
|
|
|
+ \vspace{8em}
|
|
|
+ \textcolor{red}{\normalsize Many shared-memory codes scale poorly \\
|
|
|
+ because they don't account for NUMA!}
|
|
|
+ %>>>
|
|
|
+ \end{overprint}
|
|
|
+
|
|
|
+ \column{0.05\textwidth}
|
|
|
+ \column{0.35\textwidth}
|
|
|
+
|
|
|
+ \begin{overprint}
|
|
|
+ \onslide<1>%<<<
|
|
|
+ Set thread affinity:
|
|
|
+ \begin{minted}[autogobble,fontsize=\footnotesize]{text}
|
|
|
+ export OMP_PLACES=cores
|
|
|
+ export OMP_PROC_BIND=spread
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+ \onslide<2->%<<<
|
|
|
+ \vspace{-1.5em}
|
|
|
+ \begin{minted}[autogobble,fontsize=\footnotesize]{text}
|
|
|
+ \end{minted}
|
|
|
+ {\footnotesize \underline{Original:}}
|
|
|
+ \begin{minted}[autogobble,fontsize=\footnotesize]{text}
|
|
|
+ Writing to array
|
|
|
+ Bandwidth = 35.4136 GB/s
|
|
|
+ \end{minted}
|
|
|
+ \vspace{0.1ex}
|
|
|
+ \begin{minted}[autogobble,fontsize=\footnotesize]{text}
|
|
|
+ Reading from array
|
|
|
+ Bandwidth = 69.4623 GB/s
|
|
|
+ \end{minted}
|
|
|
+ \vspace{0.1ex}
|
|
|
+ \begin{minted}[autogobble,fontsize=\footnotesize]{text}
|
|
|
+ Adding arrays
|
|
|
+ Bandwidth = 113.637 GB/s
|
|
|
+ \end{minted}
|
|
|
+
|
|
|
+ \vspace{0.2em}
|
|
|
+ {\footnotesize \underline{NUMA aware:}}
|
|
|
+ \begin{minted}[autogobble,fontsize=\footnotesize]{text}
|
|
|
+ Writing to array
|
|
|
+ Bandwidth = 87.1515 GB/s
|
|
|
+ \end{minted}
|
|
|
+ \vspace{0.1ex}
|
|
|
+ \begin{minted}[autogobble,fontsize=\footnotesize]{text}
|
|
|
+ Reading from array
|
|
|
+ Bandwidth = 160.663 GB/s
|
|
|
+ \end{minted}
|
|
|
+ \vspace{0.1ex}
|
|
|
+ \begin{minted}[autogobble,fontsize=\footnotesize]{text}
|
|
|
+ Adding arrays
|
|
|
+ Bandwidth = 180.069 GB/s
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+ \end{overprint}
|
|
|
+
|
|
|
+ \end{columns}
|
|
|
+
|
|
|
+\end{frame}
|
|
|
+%>>>
|
|
|
+
|
|
|
+\begin{frame} \frametitle{Memory bandwidth and latency}{} %<<<
|
|
|
+
|
|
|
+ \begin{columns}
|
|
|
+ \column{0.5\textwidth}
|
|
|
+ \center
|
|
|
+ {$32\times$ difference between \\
|
|
|
+ L1 and main memory bandwidth!}
|
|
|
+
|
|
|
+ \vspace{1em}
|
|
|
+ \resizebox{1.0\textwidth}{!}{\begin{tikzpicture} %<<<
|
|
|
+ \begin{loglogaxis}[width=12cm,height=8cm, xmin=8192, xmax=256000000, ymin=80, ymax=6000,
|
|
|
+ xlabel={array size per core (bytes)}, ylabel=Bandwidth (GB/s), legend pos=south west, legend style={draw=none}]
|
|
|
+
|
|
|
+ \addplot[mark=none, thick, color=blue] table [x={size}, y={read-bw}] {data/bw.txt};
|
|
|
+ \addplot[mark=none, thick, color=red] table [x={size}, y={write-bw}] {data/bw.txt};
|
|
|
+ \addplot[mark=none, thick, color=black] table [x={size}, y={vecadd-bw}] {data/bw.txt};
|
|
|
+
|
|
|
+ \addplot[mark=none, color=gray, thick] coordinates { (32768,8) (32768,80000)};
|
|
|
+ \addplot[mark=none, color=gray, thick] coordinates { (1048576,8) (1048576,80000)};
|
|
|
+ \addplot[mark=none, color=gray, thick] coordinates { (3244032,8) (3244032,80000)};
|
|
|
+ \legend{{read-bw},{write-bw},{read+write-bw}}
|
|
|
+ \end{loglogaxis}
|
|
|
+ \end{tikzpicture}} %>>>
|
|
|
+ \column{0.5\textwidth}
|
|
|
+ \center
|
|
|
+ {$56\times$ difference between \\
|
|
|
+ L1 and main memory latency!}
|
|
|
+
|
|
|
+ \vspace{1em}
|
|
|
+ \resizebox{1.0\textwidth}{!}{\begin{tikzpicture} %<<<
|
|
|
+ \begin{loglogaxis}[width=12cm,height=8cm, xmin=8192, xmax=256000000, ymin=4, ymax=300,
|
|
|
+ xlabel={array size (bytes)}, ylabel=cycles, legend pos=north west, legend style={draw=none}]
|
|
|
+
|
|
|
+ \addplot[mark=none, thick, color=black] table [x={bytes}, y={cycles}] {data/latency.txt};
|
|
|
+
|
|
|
+ \addplot[mark=none, color=gray, thick] coordinates { (32768,1) (32768,5000)};
|
|
|
+ \addplot[mark=none, color=gray, thick] coordinates { (1048576,1) (1048576,5000)};
|
|
|
+ \addplot[mark=none, color=gray, thick] coordinates {(25952256,1) (25952256,5000)};
|
|
|
+ \legend{{latency}}
|
|
|
+ \end{loglogaxis}
|
|
|
+ \end{tikzpicture}} %>>>
|
|
|
+ \end{columns}
|
|
|
+
|
|
|
+\end{frame}
|
|
|
+%>>>
|
|
|
+
|
|
|
+
|
|
|
+\begin{frame}[fragile] \frametitle{Optimizing GEMM for memory access}{} %<<<
|
|
|
+
|
|
|
+ \begin{columns}
|
|
|
+ \column{0.5\textwidth}
|
|
|
+ \begin{overprint}
|
|
|
+ \onslide<1->%<<<
|
|
|
+ \resizebox{0.99\textwidth}{!}{\begin{tikzpicture} %<<<
|
|
|
+
|
|
|
+ \node at (-0.5,-1) {$M$};
|
|
|
+ \node at (1,0.5) {$N$};
|
|
|
+ \draw[latex-latex, thick] (0,0.25) -- (2,0.25);
|
|
|
+ \draw[latex-latex, thick] (-0.25,0) -- (-0.25,-2);
|
|
|
+ \fill[c2] (0,0) rectangle (2,-2);
|
|
|
+ \draw[step=0.25,thick, darkgray] (0,0) grid (2,-2);
|
|
|
+ \node at (1,-1) {\Large C};
|
|
|
+
|
|
|
+ \node at (2.5,-1) {$=$};
|
|
|
+
|
|
|
+ \node at (4.25,0.5) {$K$};
|
|
|
+ \draw[latex-latex, thick] (3,0.25) -- (5.5,0.25);
|
|
|
+ \fill[c3] (3,0) rectangle (5.5,-2);
|
|
|
+ \draw[step=0.25,thick, darkgray] (2.99,0) grid (5.5,-2);
|
|
|
+ \node at (4.25,-1) {\Large A};
|
|
|
+
|
|
|
+ \node at (6,-1) {$\times$};
|
|
|
+
|
|
|
+ \fill[c4] (6.5,0) rectangle (8.5,-2.5);
|
|
|
+ \draw[step=0.25,thick, darkgray] (6.49,0) grid (8.5,-2.5);
|
|
|
+ \node at (7.5,-1.25) {\Large B};
|
|
|
+ \end{tikzpicture}}%>>>
|
|
|
+ \begin{minted}[
|
|
|
+ frame=lines,
|
|
|
+ fontsize=\scriptsize,
|
|
|
+ baselinestretch=1,
|
|
|
+ numbersep=5pt,
|
|
|
+ linenos,
|
|
|
+ autogobble,
|
|
|
+ framesep=1mm,
|
|
|
+ mathescape
|
|
|
+ ]{C++}
|
|
|
+ void GEMM(int M, int N, int K, double* A, int LDA,
|
|
|
+ double* B, int LDB, double* C, int LDC) {
|
|
|
+ for (int j = 0; j < N; j++)
|
|
|
+ for (int k = 0; k < K; k++)
|
|
|
+ for (int i = 0; i < M; i++)
|
|
|
+ C[i+j*LDC] += A[i+k*LDA] * B[k+j*LDB];
|
|
|
+ }
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+ \qquad \qquad {\small M = N = K = 2000}
|
|
|
+ \end{overprint}
|
|
|
+
|
|
|
+ \column{0.05\textwidth}
|
|
|
+ \column{0.5\textwidth}
|
|
|
+ \begin{overprint}
|
|
|
+ \onslide<1>%<<<
|
|
|
+ \begin{minted}[autogobble,fontsize=\footnotesize]{text}
|
|
|
+ \end{minted}
|
|
|
+ {\bf perf:} performance monitoring tool which samples hardware counters
|
|
|
+ %>>>
|
|
|
+ \onslide<2->%<<<
|
|
|
+ \begin{minted}[autogobble,fontsize=\footnotesize]{text}
|
|
|
+ \end{minted}
|
|
|
+ {\bf perf:} performance monitoring tool which samples hardware counters
|
|
|
+
|
|
|
+ \vspace{1em}
|
|
|
+ \begin{minted}[autogobble,fontsize=\scriptsize]{text}
|
|
|
+ ~> g++ -O3 -march=native gemm.cpp
|
|
|
+ ~> perf stat -e L1-dcache-load-misses \
|
|
|
+ -e L1-dcache-loads -e l2_rqsts.miss \
|
|
|
+ -e l2_rqsts.references -e LLC-load-misses \
|
|
|
+ -e LLC-loads ./a.out
|
|
|
+
|
|
|
+ FLOP rate = 4.87547 GFLOP/s
|
|
|
+
|
|
|
+ 30,311,624,911 L1-dcache-loads
|
|
|
+ 14,900,283,807 L1-dcache-load-misses 49.16% of all L1-dcache accesses
|
|
|
+ 24,387,281,512 l2_rqsts.references
|
|
|
+ 10,034,752,513 l2_rqsts.miss
|
|
|
+ 2,260,778,457 LLC-loads
|
|
|
+ 1,310,606,484 LLC-load-misses 57.97% of all LL-cache accesses
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+ \end{overprint}
|
|
|
+ \end{columns}
|
|
|
+
|
|
|
+\end{frame}
|
|
|
+%>>>
|
|
|
+
|
|
|
+\begin{frame}[fragile] \frametitle{GEMM blocking}{} %<<<
|
|
|
+
|
|
|
+ \begin{columns}
|
|
|
+ \column{0.5\textwidth}
|
|
|
+ \begin{overprint}
|
|
|
+ \onslide<1>%<<<
|
|
|
+ \begin{minted}[
|
|
|
+ frame=lines,
|
|
|
+ fontsize=\scriptsize,
|
|
|
+ baselinestretch=1,
|
|
|
+ numbersep=5pt,
|
|
|
+ linenos,
|
|
|
+ autogobble,
|
|
|
+ framesep=1mm,
|
|
|
+ mathescape
|
|
|
+ ]{C++}
|
|
|
+ template <int M, int N, int K>
|
|
|
+ void GEMM_blocked(double* A, int LDA,
|
|
|
+ double* B, int LDB, double* C, int LDC) {
|
|
|
+ for (int j = 0; j < N; j++)
|
|
|
+ for (int k = 0; k < K; k++)
|
|
|
+ for (int i = 0; i < M; i++)
|
|
|
+ C[i+j*LDC] += A[i+k*LDA] * B[k+j*LDB];
|
|
|
+ }
|
|
|
+
|
|
|
+ template <int M, int N, int K,
|
|
|
+ int Mb, int Nb, int Kb, int... NN>
|
|
|
+ void GEMM_blocked(double* A, int LDA,
|
|
|
+ double* B, int LDB, double* C, int LDC) {
|
|
|
+ for (int j = 0; j < N; j+=Nb)
|
|
|
+ for (int i = 0; i < M; i+=Mb)
|
|
|
+ for (int k = 0; k < K; k+=Kb)
|
|
|
+ GEMM_blocked<Mb,Nb,Kb, NN...>(A+i+k*LDA,LDA,
|
|
|
+ B+k+j*LDB,LDB, C+i+j*LDC,LDC);
|
|
|
+ }
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+ \onslide<2->%<<<
|
|
|
+ \begin{minted}[
|
|
|
+ frame=lines,
|
|
|
+ fontsize=\scriptsize,
|
|
|
+ baselinestretch=1,
|
|
|
+ numbersep=5pt,
|
|
|
+ linenos,
|
|
|
+ autogobble,
|
|
|
+ framesep=1mm,
|
|
|
+ mathescape
|
|
|
+ ]{C++}
|
|
|
+ template <int M, int N, int K>
|
|
|
+ void GEMM_blocked(double* A, int LDA,
|
|
|
+ double* B, int LDB, double* C, int LDC) {
|
|
|
+ GEMM_ker_vec_unrolled<M,N,K>(A,LDA, B,LDB, C,LDC);
|
|
|
+ }
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+ template <int M, int N, int K,
|
|
|
+ int Mb, int Nb, int Kb, int... NN>
|
|
|
+ void GEMM_blocked(double* A, int LDA,
|
|
|
+ double* B, int LDB, double* C, int LDC) {
|
|
|
+ for (int j = 0; j < N; j+=Nb)
|
|
|
+ for (int i = 0; i < M; i+=Mb)
|
|
|
+ for (int k = 0; k < K; k+=Kb)
|
|
|
+ GEMM_blocked<Mb,Nb,Kb, NN...>(A+i+k*LDA,LDA,
|
|
|
+ B+k+j*LDB,LDB, C+i+j*LDC,LDC);
|
|
|
+ }
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+ \end{overprint}
|
|
|
+
|
|
|
+ \column{0.05\textwidth}
|
|
|
+ \column{0.55\textwidth}
|
|
|
+ \begin{overprint}
|
|
|
+ \onslide<1-2>%<<<
|
|
|
+ \begin{minted}[autogobble,fontsize=\scriptsize]{text}
|
|
|
+ \end{minted}
|
|
|
+
|
|
|
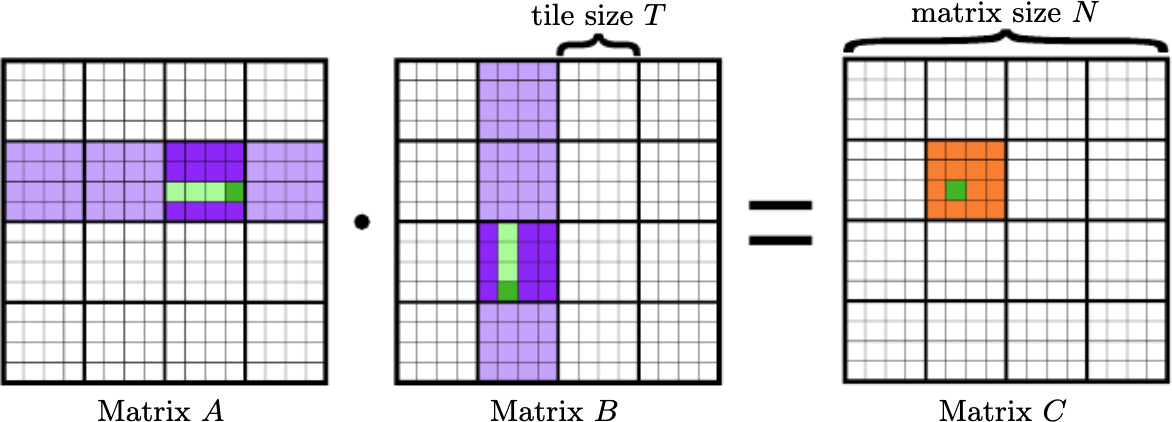
+ \includegraphics[width=0.99\textwidth]{figs/gemm-tiling}
|
|
|
+ %>>>
|
|
|
+ \onslide<3>%<<<
|
|
|
+ \begin{minted}[autogobble,fontsize=\scriptsize]{text}
|
|
|
+ \end{minted}
|
|
|
+
|
|
|
+ {\small GEMM\_blocked<M,N,K, 8,10,40>(...)}
|
|
|
+
|
|
|
+ \begin{minted}[autogobble,fontsize=\scriptsize]{text}
|
|
|
+ FLOP rate = 11.803 GFLOP/s
|
|
|
+ 11,514,598,988 L1-dcache-loads
|
|
|
+ 3,274,256,252 L1-dcache-load-misses 28.44% of all L1-dcache accesses
|
|
|
+ 3,283,717,404 l2_rqsts.references
|
|
|
+ 1,047,408,896 l2_rqsts.miss
|
|
|
+ 1,032,604,200 LLC-loads
|
|
|
+ 293,256,535 LLC-load-misses 28.40% of all LL-cache accesses
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+ \onslide<4>%<<<
|
|
|
+ \begin{minted}[autogobble,fontsize=\scriptsize]{text}
|
|
|
+ \end{minted}
|
|
|
+
|
|
|
+ {\small GEMM\_blocked<M,N,K, 8,10,40>(...)}
|
|
|
+
|
|
|
+ \begin{minted}[autogobble,fontsize=\scriptsize]{text}
|
|
|
+ FLOP rate = 11.803 GFLOP/s
|
|
|
+ 11,514,598,988 L1-dcache-loads
|
|
|
+ 3,274,256,252 L1-dcache-load-misses 28.44% of all L1-dcache accesses
|
|
|
+ 3,283,717,404 l2_rqsts.references
|
|
|
+ 1,047,408,896 l2_rqsts.miss
|
|
|
+ 1,032,604,200 LLC-loads
|
|
|
+ 293,256,535 LLC-load-misses 28.40% of all LL-cache accesses
|
|
|
+ \end{minted}
|
|
|
+
|
|
|
+ \vspace{0.5em}
|
|
|
+ {\small GEMM\_blocked<M,N,K, 40,40,40, 8,10,40>(...)}
|
|
|
+
|
|
|
+ \begin{minted}[autogobble,fontsize=\scriptsize]{text}
|
|
|
+ FLOP rate = 26.5831 GFLOP/s
|
|
|
+ 11,533,695,903 L1-dcache-loads
|
|
|
+ 1,084,624,171 L1-dcache-load-misses 9.40% of all L1-dcache accesses
|
|
|
+ 1,091,155,596 l2_rqsts.references
|
|
|
+ 538,256,077 l2_rqsts.miss
|
|
|
+ 470,615,736 LLC-loads
|
|
|
+ 112,816,293 LLC-load-misses 23.97% of all LL-cache accesses
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+ \onslide<5>%<<<
|
|
|
+ \begin{minted}[autogobble,fontsize=\scriptsize]{text}
|
|
|
+ \end{minted}
|
|
|
+
|
|
|
+ {\small GEMM\_blocked<M,N,K, 40,40,40, 8,10,40>(...)}
|
|
|
+
|
|
|
+ \begin{minted}[autogobble,fontsize=\scriptsize]{text}
|
|
|
+ FLOP rate = 26.5831 GFLOP/s
|
|
|
+ 11,533,695,903 L1-dcache-loads
|
|
|
+ 1,084,624,171 L1-dcache-load-misses 9.40% of all L1-dcache accesses
|
|
|
+ 1,091,155,596 l2_rqsts.references
|
|
|
+ 538,256,077 l2_rqsts.miss
|
|
|
+ 470,615,736 LLC-loads
|
|
|
+ 112,816,293 LLC-load-misses 23.97% of all LL-cache accesses
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+ \onslide<6>%<<<
|
|
|
+ \begin{minted}[autogobble,fontsize=\scriptsize]{text}
|
|
|
+ \end{minted}
|
|
|
+
|
|
|
+ {\small GEMM\_blocked<M,N,K, 40,40,40, 8,10,40>(...)}
|
|
|
+
|
|
|
+ \begin{minted}[autogobble,fontsize=\scriptsize]{text}
|
|
|
+ FLOP rate = 26.5831 GFLOP/s
|
|
|
+ 11,533,695,903 L1-dcache-loads
|
|
|
+ 1,084,624,171 L1-dcache-load-misses 9.40% of all L1-dcache accesses
|
|
|
+ 1,091,155,596 l2_rqsts.references
|
|
|
+ 538,256,077 l2_rqsts.miss
|
|
|
+ 470,615,736 LLC-loads
|
|
|
+ 112,816,293 LLC-load-misses 23.97% of all LL-cache accesses
|
|
|
+ \end{minted}
|
|
|
+
|
|
|
+ {\small GEMM\_blocked<M,N,K, 200,200,200, \\
|
|
|
+ \phantom{000000000000000000} 40,40,40, 8,10,40>(...)}
|
|
|
+
|
|
|
+ \begin{minted}[autogobble,fontsize=\scriptsize]{text}
|
|
|
+ FLOP rate = 43.1604 GFLOP/s
|
|
|
+ 11,531,903,350 L1-dcache-loads
|
|
|
+ 1,094,841,388 L1-dcache-load-misses 9.49% of all L1-dcache accesses
|
|
|
+ 1,194,502,755 l2_rqsts.references
|
|
|
+ 201,888,454 l2_rqsts.miss
|
|
|
+ 116,940,584 LLC-loads
|
|
|
+ 44,894,302 LLC-load-misses 38.39% of all LL-cache accesses
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+ \end{overprint}
|
|
|
+ \end{columns}
|
|
|
+
|
|
|
+\end{frame}
|
|
|
+%>>>
|
|
|
+
|
|
|
+
|
|
|
+\begin{frame} \frametitle{Memory and caches summary}{} %<<<
|
|
|
+
|
|
|
+ \begin{itemize}
|
|
|
+ \item test
|
|
|
+ \end{itemize}
|
|
|
|
|
|
% many ways to shoot yourself in the foot:
|
|
|
|
|
|
@@ -55,23 +906,25 @@
|
|
|
% locks / atomic / synchronization
|
|
|
|
|
|
\end{frame}
|
|
|
+%>>>
|
|
|
|
|
|
-\begin{frame} \frametitle{Cache Coherent Non-uniform Memory Access}{} %<<<
|
|
|
|
|
|
-\begin{itemize}
|
|
|
- \item {\bf Cores:} individual processing units.
|
|
|
- \item {\bf Sockets:} collection of cores on the same silicon die.
|
|
|
- \item Each sockets connected to its own DRAM.
|
|
|
- \item Sockets interconnected using a network: QPI (Intel), HT (AMD).
|
|
|
- \item Location of memory pages determined by first-touch policy.
|
|
|
-\end{itemize}
|
|
|
|
|
|
- \center
|
|
|
- \includegraphics[width=0.7\textwidth]{figs/numa.png}
|
|
|
|
|
|
- {\footnotesize Source: https://www.boost.org}
|
|
|
-\end{frame} %>>>
|
|
|
|
|
|
+% Stack vs heap memory
|
|
|
+% vector vs linked list
|
|
|
|
|
|
-%>>>
|
|
|
+%\begin{frame} \frametitle{Shared memory pitfalls}{} %<<<
|
|
|
+%
|
|
|
+% % many ways to shoot yourself in the foot:
|
|
|
+%
|
|
|
+% % thread contention
|
|
|
+% % cache coherency
|
|
|
+% % thread pinning
|
|
|
+% % NUMA
|
|
|
+% % locks / atomic / synchronization
|
|
|
+%
|
|
|
+%\end{frame}
|
|
|
+%%>>>
|
|
|
|

{kind=link}
{kind=link}
{kind=link}