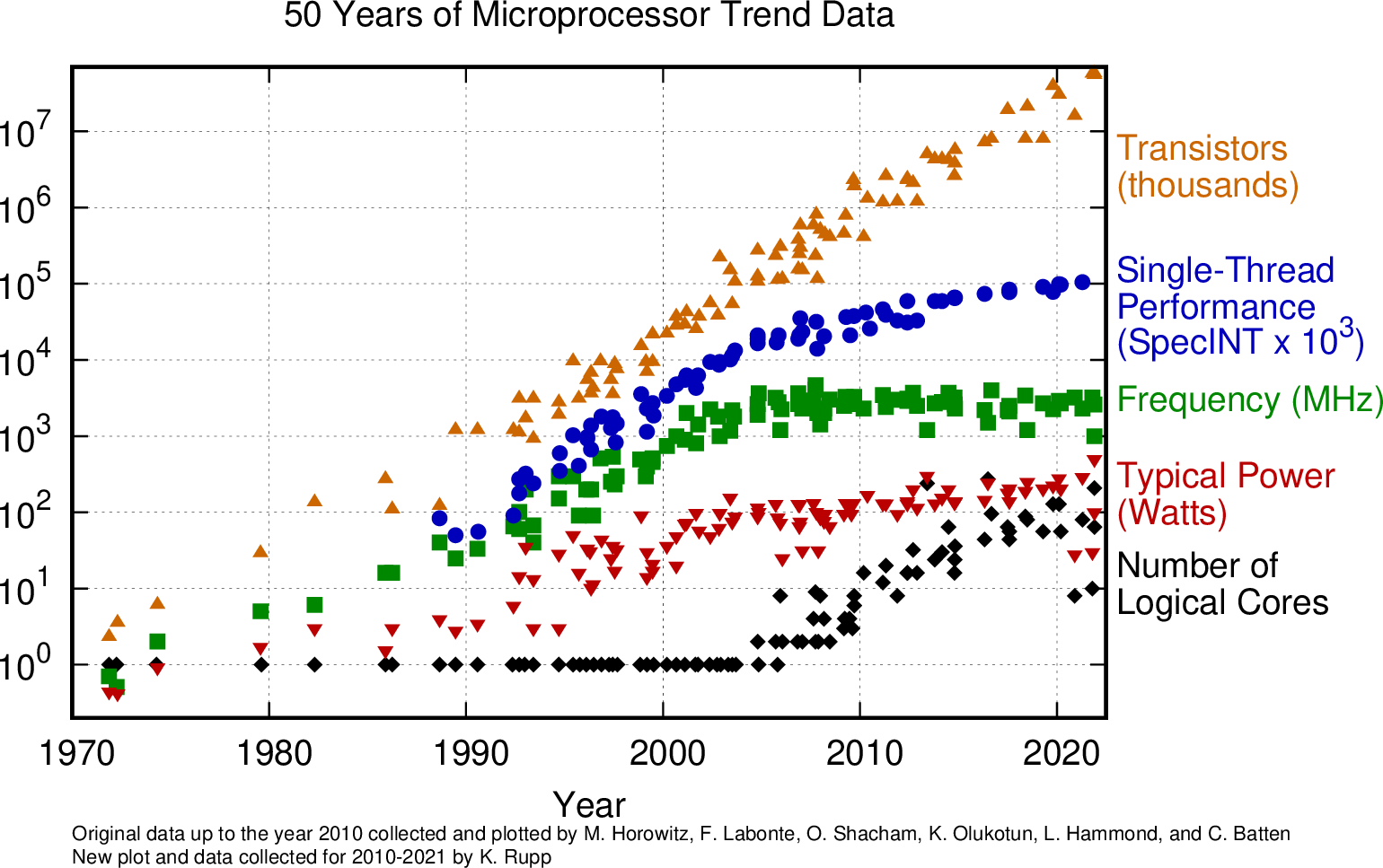
|
|
@@ -3,14 +3,14 @@
|
|
|
\section{Instruction level optimization}
|
|
|
% https://www.youtube.com/watch?v=BP6NxVxDQIs
|
|
|
|
|
|
- %<<< How code executes on a computer
|
|
|
+%<<< How code executes on a computer
|
|
|
\begingroup
|
|
|
\setbeamertemplate{background canvas}{%
|
|
|
\begin{tikzpicture}[remember picture,overlay]
|
|
|
\only<3>{
|
|
|
-\draw[line width=20pt,red!60!black]
|
|
|
+\draw[line width=20pt,red!60!black]
|
|
|
(11,-2) -- (15,-8);
|
|
|
-\draw[line width=20pt,red!60!black]
|
|
|
+\draw[line width=20pt,red!60!black]
|
|
|
(15,-2) -- (11,-8);
|
|
|
}
|
|
|
\end{tikzpicture}}
|
|
|
@@ -74,9 +74,9 @@
|
|
|
\begin{itemize}
|
|
|
\setlength\itemsep{0.75em}
|
|
|
\item code executes line-by-line
|
|
|
+ \item sequentially and in order
|
|
|
\item one scalar operation at a time
|
|
|
\item one operation per clock cycle
|
|
|
- \item sequentially and in order
|
|
|
\end{itemize}
|
|
|
\only<2>{}
|
|
|
|
|
|
@@ -106,9 +106,9 @@
|
|
|
\node at (0,0) {\includegraphics[width=0.9\textwidth]{figs/skylake-arch}};
|
|
|
}
|
|
|
\only<2>{
|
|
|
- \node[opacity=0] at (0,0) {\includegraphics[width=0.9\textwidth]{figs/skylake-arch}};
|
|
|
+ \node[opacity=0] at (0,-1) {\includegraphics[width=0.9\textwidth]{figs/skylake-arch}};
|
|
|
\node at (0,0) {\includegraphics[width=0.99\textwidth]{figs/skylake_scheduler}};
|
|
|
- \node at (0,-3) {\small Skylake micro-architecture (wikichip.org)};
|
|
|
+ \node at (0,-3) {\small Skylake micro-architecture (source: wikichip.org)};
|
|
|
}
|
|
|
\end{tikzpicture}}
|
|
|
|
|
|
@@ -167,7 +167,7 @@
|
|
|
\center
|
|
|
\includegraphics[width=0.8\textwidth]{figs/intel-core-gflops}
|
|
|
|
|
|
- {\footnotesize John McCalpin - Memory bandwidth and system balance in HPC systems, 2016}
|
|
|
+ {\footnotesize Source: John McCalpin - Memory bandwidth and system balance in HPC systems, 2016}
|
|
|
|
|
|
\end{frame}
|
|
|
%>>>
|
|
|
@@ -377,6 +377,8 @@
|
|
|
\item Vector Class Library - Agner Fog\\
|
|
|
\url{https://github.com/vectorclass/version2}
|
|
|
|
|
|
+ \item SLEEF Vectorized Math Library \\
|
|
|
+
|
|
|
\item SCTL (\url{https://github.com/dmalhotra/SCTL})
|
|
|
|
|
|
\item Similar proposals for future C++ standard library \\
|
|
|
@@ -528,8 +530,7 @@
|
|
|
\begin{overprint}
|
|
|
\onslide<2>%<<<
|
|
|
\begin{minted}[gobble=8,fontsize=\footnotesize]{text}
|
|
|
- $ g++ -O3 -march=native -fopenmp test.cpp
|
|
|
- $ ./a.out
|
|
|
+
|
|
|
T = 1.22806
|
|
|
cycles/iter = 4.05259
|
|
|
\end{minted}
|
|
|
@@ -539,8 +540,7 @@
|
|
|
|
|
|
\onslide<3>%<<<
|
|
|
\begin{minted}[gobble=8,fontsize=\footnotesize]{text}
|
|
|
- $ g++ -O3 -march=native -fopenmp test.cpp
|
|
|
- $ ./a.out
|
|
|
+
|
|
|
T = 1.22806
|
|
|
cycles/iter = 4.05259
|
|
|
\end{minted}
|
|
|
@@ -552,8 +552,7 @@
|
|
|
|
|
|
\onslide<4>%<<<
|
|
|
\begin{minted}[gobble=8,fontsize=\footnotesize]{text}
|
|
|
- $ g++ -O3 -march=native -fopenmp test.cpp
|
|
|
- $ ./a.out
|
|
|
+
|
|
|
T = 1.22806
|
|
|
cycles/iter = 4.05259
|
|
|
\end{minted}
|
|
|
@@ -562,8 +561,7 @@
|
|
|
\vspace{0.5em}
|
|
|
\qquad --- floating-point division ---
|
|
|
\begin{minted}[gobble=8,fontsize=\footnotesize]{text}
|
|
|
- $ g++ -O3 -march=native -fopenmp test.cpp
|
|
|
- $ ./a.out
|
|
|
+
|
|
|
T = 39.1521
|
|
|
cycles/iter = 129.202
|
|
|
\end{minted}
|
|
|
@@ -573,8 +571,7 @@
|
|
|
|
|
|
\onslide<5->%<<<
|
|
|
\begin{minted}[gobble=8,fontsize=\footnotesize]{text}
|
|
|
- $ g++ -O3 -march=native -fopenmp test.cpp
|
|
|
- $ ./a.out
|
|
|
+
|
|
|
T = 1.22806
|
|
|
cycles/iter = 4.05259
|
|
|
\end{minted}
|
|
|
@@ -583,8 +580,7 @@
|
|
|
\vspace{0.5em}
|
|
|
\qquad --- floating-point division ---
|
|
|
\begin{minted}[gobble=8,fontsize=\footnotesize]{text}
|
|
|
- $ g++ -O3 -march=native -fopenmp test.cpp
|
|
|
- $ ./a.out
|
|
|
+
|
|
|
T = 39.1521
|
|
|
cycles/iter = 129.202
|
|
|
\end{minted}
|
|
|
@@ -725,9 +721,9 @@
|
|
|
\end{frame}
|
|
|
%>>>
|
|
|
|
|
|
-\begin{frame}[fragile] \frametitle{Pipelining: polynomial eval (Estrin's method)} %<<<
|
|
|
+\begin{frame}[t,fragile] \frametitle{Pipelining: polynomial eval (Estrin's method)} %<<<
|
|
|
|
|
|
- \begin{columns}[T]
|
|
|
+ \begin{columns}[t]
|
|
|
\column{0.75\textwidth}
|
|
|
{\bf Input:} \\
|
|
|
x,~a,~b,~c,~d,~e,~f,~g,~h \\
|
|
|
@@ -866,80 +862,6 @@
|
|
|
|
|
|
\end{tikzpicture}}%
|
|
|
%>>>
|
|
|
- %%<<<
|
|
|
- %\textcolor{c1}{x\textsuperscript{2} = x * x} \only<1-4>{ $\leftarrow$} \\
|
|
|
- %\textcolor{c2}{x\textsuperscript{4} = x\textsuperscript{2} * x\textsuperscript{2}}\only<5-8>{ $\leftarrow$} \\
|
|
|
- %\textcolor{c3}{u = a * x + b} \only<2-5>{ $\leftarrow$} \\
|
|
|
- %\textcolor{c4}{v = c * x + d} \only<3-6>{ $\leftarrow$} \\
|
|
|
- %\textcolor{c5}{w = e * x + f} \only<4-7>{ $\leftarrow$} \\
|
|
|
- %\textcolor{c6}{p = g * x + h} \only<6-9>{ $\leftarrow$} \\
|
|
|
- %\textcolor{c7}{q = u * x\textsuperscript{2} + v} \only<7-10>{ $\leftarrow$} \\
|
|
|
- %\textcolor{c8}{r = w * x\textsuperscript{2} + p} \only<10-13>{ $\leftarrow$} \\
|
|
|
- %\textcolor{c9}{s = q * x\textsuperscript{4} + r} \only<14-17>{ $\leftarrow$} \\
|
|
|
-
|
|
|
- %\vspace{0.5em}
|
|
|
- %{\bf Pipeline:}
|
|
|
-
|
|
|
- %\vspace{0.1em}
|
|
|
- %\resizebox{0.99\textwidth}{!}{\begin{tikzpicture}
|
|
|
- % \draw[draw=none] (0,0) rectangle (4,1);
|
|
|
- % \only<1-17>{
|
|
|
- % \draw[fill=white] (0,0) rectangle (1,1);
|
|
|
- % \draw[fill=white] (1,0) rectangle (2,1);
|
|
|
- % \draw[fill=white] (2,0) rectangle (3,1);
|
|
|
- % \draw[fill=white] (3,0) rectangle (4,1);
|
|
|
- % }
|
|
|
-
|
|
|
- % \only<1>{\draw[fill=c1] (0,0) rectangle (1,1);}
|
|
|
- % \only<2>{\draw[fill=c1] (1,0) rectangle (2,1);}
|
|
|
- % \only<3>{\draw[fill=c1] (2,0) rectangle (3,1);}
|
|
|
- % \only<4>{\draw[fill=c1] (3,0) rectangle (4,1);}
|
|
|
-
|
|
|
- % \only<5>{\draw[fill=c2] (0,0) rectangle (1,1);}
|
|
|
- % \only<6>{\draw[fill=c2] (1,0) rectangle (2,1);}
|
|
|
- % \only<7>{\draw[fill=c2] (2,0) rectangle (3,1);}
|
|
|
- % \only<8>{\draw[fill=c2] (3,0) rectangle (4,1);}
|
|
|
-
|
|
|
- % \only<2>{\draw[fill=c3] (0,0) rectangle (1,1);}
|
|
|
- % \only<3>{\draw[fill=c3] (1,0) rectangle (2,1);}
|
|
|
- % \only<4>{\draw[fill=c3] (2,0) rectangle (3,1);}
|
|
|
- % \only<5>{\draw[fill=c3] (3,0) rectangle (4,1);}
|
|
|
- %
|
|
|
- % \only<3>{\draw[fill=c4] (0,0) rectangle (1,1);}
|
|
|
- % \only<4>{\draw[fill=c4] (1,0) rectangle (2,1);}
|
|
|
- % \only<5>{\draw[fill=c4] (2,0) rectangle (3,1);}
|
|
|
- % \only<6>{\draw[fill=c4] (3,0) rectangle (4,1);}
|
|
|
- %
|
|
|
- % \only<4>{\draw[fill=c5] (0,0) rectangle (1,1);}
|
|
|
- % \only<5>{\draw[fill=c5] (1,0) rectangle (2,1);}
|
|
|
- % \only<6>{\draw[fill=c5] (2,0) rectangle (3,1);}
|
|
|
- % \only<7>{\draw[fill=c5] (3,0) rectangle (4,1);}
|
|
|
- %
|
|
|
- % \only<6>{\draw[fill=c6] (0,0) rectangle (1,1);}
|
|
|
- % \only<7>{\draw[fill=c6] (1,0) rectangle (2,1);}
|
|
|
- % \only<8>{\draw[fill=c6] (2,0) rectangle (3,1);}
|
|
|
- % \only<9>{\draw[fill=c6] (3,0) rectangle (4,1);}
|
|
|
-
|
|
|
- % \only<7>{\draw[fill=c7] (0,0) rectangle (1,1);}
|
|
|
- % \only<8>{\draw[fill=c7] (1,0) rectangle (2,1);}
|
|
|
- % \only<9>{\draw[fill=c7] (2,0) rectangle (3,1);}
|
|
|
- % \only<10>{\draw[fill=c7] (3,0) rectangle (4,1);}
|
|
|
-
|
|
|
- % \only<10>{\draw[fill=c8] (0,0) rectangle (1,1);}
|
|
|
- % \only<11>{\draw[fill=c8] (1,0) rectangle (2,1);}
|
|
|
- % \only<12>{\draw[fill=c8] (2,0) rectangle (3,1);}
|
|
|
- % \only<13>{\draw[fill=c8] (3,0) rectangle (4,1);}
|
|
|
-
|
|
|
- % \only<14>{\draw[fill=c9] (0,0) rectangle (1,1);}
|
|
|
- % \only<15>{\draw[fill=c9] (1,0) rectangle (2,1);}
|
|
|
- % \only<16>{\draw[fill=c9] (2,0) rectangle (3,1);}
|
|
|
- % \only<17>{\draw[fill=c9] (3,0) rectangle (4,1);}
|
|
|
-
|
|
|
- % \only<18>{\node at (2,0.75) {\Large 17 cycles};}
|
|
|
- % \only<18>{\node at (2,0.25) {\Large 60\% faster!};}
|
|
|
-
|
|
|
- %\end{tikzpicture}}%
|
|
|
- %%>>>
|
|
|
|
|
|
\end{columns}
|
|
|
|
|
|
@@ -1038,7 +960,7 @@
|
|
|
T = 8.82432
|
|
|
cycles/iter = 29.1203
|
|
|
|
|
|
-
|
|
|
+
|
|
|
Using Estrin's method:
|
|
|
T = 5.7813
|
|
|
cycles/iter = 19.0783
|
|
|
@@ -1054,8 +976,8 @@
|
|
|
T = 8.82432
|
|
|
cycles/iter = 29.1203
|
|
|
|
|
|
-
|
|
|
- Using Estrin's method:
|
|
|
+
|
|
|
+ Using Estrin's method (unrolled):
|
|
|
T = 4.5794
|
|
|
cycles/iter = 15.112
|
|
|
\end{minted}
|
|
|
@@ -1070,45 +992,323 @@
|
|
|
\end{frame}
|
|
|
%>>>
|
|
|
|
|
|
-\begin{frame} \frametitle{Libraries for special function evaluation} %<<<
|
|
|
- % Fast function evaluation using polynomial evaluation
|
|
|
- % baobzi
|
|
|
-
|
|
|
- % sf_benchmarks : https://github.com/flatironinstitute/sf_benchmarks
|
|
|
- % Baobzi (adaptive fast function interpolator)
|
|
|
- % Agner Fog's Vector Class Library
|
|
|
- % SLEEF Vectoried Math Library
|
|
|
- % FORTRAN native routines
|
|
|
- % C++ Standard Library
|
|
|
- % Eigen
|
|
|
- % Boost
|
|
|
- % AMD Math Library (LibM)
|
|
|
- % GNU Scientific Library (GSL)
|
|
|
- % Scientific Computing Template Library (SCTL)
|
|
|
-
|
|
|
- % func name Mevals/s cycles/eval
|
|
|
- % bessel_J0 baobzi 162.9 20.8
|
|
|
- % bessel_J0 fort 16.9 200.9
|
|
|
- % bessel_J0 gsl 6.7 504.5
|
|
|
- % bessel_J0 boost 6.2 542.9
|
|
|
- %
|
|
|
- % func name Mevals/s cycles/eval
|
|
|
- % sin agnerfog 1054.0 3.2
|
|
|
- % sin sctl 951.6 3.6
|
|
|
- % sin sleef 740.3 4.6
|
|
|
- % sin amdlibm 490.9 6.9
|
|
|
- % sin amdlibm 145.7 23.3
|
|
|
- % sin stl 103.1 32.9
|
|
|
- % sin eigen 102.5 33.1
|
|
|
- % sin gsl 22.7 149.4
|
|
|
-
|
|
|
+\begin{frame}[t] \frametitle{Libraries for special function evaluation} %<<<
|
|
|
+
|
|
|
+ \vspace{-1.1em}
|
|
|
+ \begin{columns}[t]
|
|
|
+ \column{0.6\textwidth}
|
|
|
+
|
|
|
+ \small
|
|
|
+ \begin{itemize}
|
|
|
+ \item Baobzi (adaptive fast function interpolator) \\
|
|
|
+ {\footnotesize
|
|
|
+ \url{https://github.com/flatironinstitute/baobzi}}
|
|
|
+ \item Agner Fog's Vector Class Library
|
|
|
+ \item SLEEF Vectoried Math Library
|
|
|
+ \item FORTRAN native routines
|
|
|
+ \item C++ Standard Library
|
|
|
+ \item Eigen
|
|
|
+ \item Boost
|
|
|
+ \item AMD Math Library (LibM)
|
|
|
+ \item GNU Scientific Library (GSL)
|
|
|
+ \item Scientific Computing Template Library (SCTL)
|
|
|
+ \end{itemize}
|
|
|
+
|
|
|
+ \column{0.4\textwidth}
|
|
|
+
|
|
|
+ \center
|
|
|
+ \resizebox{0.95\textwidth}{!}{ %<<<
|
|
|
+ \begin{tabular}{r r r r }
|
|
|
+ \toprule
|
|
|
+ func & name & cycles/eval \\
|
|
|
+ \midrule
|
|
|
+ bessel\_J0 & baobzi & 20.8 \\
|
|
|
+ bessel\_J0 & fort & 200.9 \\
|
|
|
+ bessel\_J0 & gsl & 504.5 \\
|
|
|
+ bessel\_J0 & boost & 542.9 \\
|
|
|
+ \midrule
|
|
|
+ sin & agnerfog & 3.2 \\
|
|
|
+ sin & sctl & 3.6 \\
|
|
|
+ sin & sleef & 4.6 \\
|
|
|
+ sin & amdlibm & 6.9 \\
|
|
|
+ sin & stl & 32.9 \\
|
|
|
+ sin & eigen & 33.1 \\
|
|
|
+ sin & gsl & 149.4 \\
|
|
|
+ \bottomrule
|
|
|
+ \end{tabular}}%>>>
|
|
|
+
|
|
|
+ \footnotesize
|
|
|
+ Robert Blackwell - sf\_benchmarks : \\
|
|
|
+ {\tiny \url{https://github.com/flatironinstitute/sf_benchmarks}}
|
|
|
+ \end{columns}
|
|
|
+
|
|
|
\end{frame}
|
|
|
%>>>
|
|
|
|
|
|
|
|
|
-\begin{frame} \frametitle{GEMM micro-kernel}{} %<<<
|
|
|
- % show different ways of vectorizing that don't work
|
|
|
- % most languages don't make it easy to specify when it is safe to vectorize (aliasing)
|
|
|
+\begin{frame}[t] \frametitle{GEMM micro-kernel}{} %<<<
|
|
|
+ \vspace{-1em}
|
|
|
+ \begin{columns}[t]
|
|
|
+ \column{0.5\textwidth}
|
|
|
+ \begin{itemize}
|
|
|
+ \setlength\itemsep{0.75em}
|
|
|
+ \item This is pedagogical -- don't write your own GEMM (use BLAS)
|
|
|
+
|
|
|
+ \item Peak FLOP rate (Skylake core)
|
|
|
+ \begin{itemize}
|
|
|
+ \item FMA (1+1 per cycle) units ($\times 2$)
|
|
|
+ \item 512-bit vectors ($\times 8$ for doubles)
|
|
|
+ \item 3.3GHz clock rate
|
|
|
+ \item $= 105.6$ GFLOP/s
|
|
|
+ \item How close can we get to the peak?
|
|
|
+ \end{itemize}
|
|
|
+
|
|
|
+ \item Matrix sizes: M, N, K
|
|
|
+
|
|
|
+ \item Assume column-major ordering
|
|
|
+
|
|
|
+ \end{itemize}
|
|
|
+ \column{0.5\textwidth}
|
|
|
+
|
|
|
+ \center
|
|
|
+ \resizebox{0.99\textwidth}{!}{\begin{tikzpicture} %<<<
|
|
|
+
|
|
|
+ \node at (-0.5,-1) {$M$};
|
|
|
+ \node at (1,0.5) {$N$};
|
|
|
+ \draw[latex-latex, thick] (0,0.25) -- (2,0.25);
|
|
|
+ \draw[latex-latex, thick] (-0.25,0) -- (-0.25,-2);
|
|
|
+ \fill[c2] (0,0) rectangle (2,-2);
|
|
|
+ \draw[step=0.25,thick, darkgray] (0,0) grid (2,-2);
|
|
|
+ \node at (1,-1) {\Large C};
|
|
|
+
|
|
|
+ \node at (2.5,-1) {$=$};
|
|
|
+
|
|
|
+ \node at (4.25,0.5) {$K$};
|
|
|
+ \draw[latex-latex, thick] (3,0.25) -- (5.5,0.25);
|
|
|
+ \fill[c3] (3,0) rectangle (5.5,-2);
|
|
|
+ \draw[step=0.25,thick, darkgray] (2.99,0) grid (5.5,-2);
|
|
|
+ \node at (4.25,-1) {\Large A};
|
|
|
+
|
|
|
+ \node at (6,-1) {$\times$};
|
|
|
+
|
|
|
+ \fill[c4] (6.5,0) rectangle (8.5,-2.5);
|
|
|
+ \draw[step=0.25,thick, darkgray] (6.49,0) grid (8.5,-2.5);
|
|
|
+ \node at (7.5,-1.25) {\Large B};
|
|
|
+ \end{tikzpicture}}%>>>
|
|
|
+
|
|
|
+ \vspace{1.5em}
|
|
|
+ \resizebox{0.4\textwidth}{!}{\begin{tikzpicture} %<<<
|
|
|
+ \fill[c2] (0,0) rectangle (1.5,-1.5);
|
|
|
+ \draw[step=0.25,thick, darkgray] (0,0) grid (1.5,-1.5);
|
|
|
+ \draw[-latex, thick] (0.125,-0.125) -- (0.125,-1.375);
|
|
|
+ \draw[-latex, thick] (0.375,-0.125) -- (0.375,-1.375);
|
|
|
+ \draw[-latex, thick] (0.625,-0.125) -- (0.625,-1.375);
|
|
|
+ \end{tikzpicture}}%>>>
|
|
|
+
|
|
|
+ \end{columns}
|
|
|
+\end{frame}
|
|
|
+%>>>
|
|
|
+
|
|
|
+\begin{frame}[t,fragile] \frametitle{GEMM micro-kernel}{} %<<<
|
|
|
+
|
|
|
+ \vspace{-1em}
|
|
|
+ \begin{columns}[t]
|
|
|
+ \column{0.55\textwidth}
|
|
|
+ \begin{overprint}
|
|
|
+ \onslide<1-2>%<<<
|
|
|
+ \begin{minted}[
|
|
|
+ frame=lines,
|
|
|
+ fontsize=\scriptsize,
|
|
|
+ linenos,
|
|
|
+ gobble=8,
|
|
|
+ mathescape
|
|
|
+ ]{C++}
|
|
|
+ template <int M, int N, int K>
|
|
|
+ void GEMM_ker_naive(double* C, double* A, double* B) {
|
|
|
+ for (int k = 0; k < K; k++)
|
|
|
+ for (int j = 0; j < M; j++)
|
|
|
+ for (int i = 0; i < M; i++)
|
|
|
+ C[i+j*M] += A[i+k*M] * B[k+K*j];
|
|
|
+ }
|
|
|
+
|
|
|
+ int main(int argc, char* argv) {
|
|
|
+ constexpr int M = 8, N = 8, K = 8;
|
|
|
+ double* C = new double[M*N];
|
|
|
+ double* A = new double[M*K];
|
|
|
+ double* B = new double[K*N];
|
|
|
+ // .. init A, B, C
|
|
|
+
|
|
|
+ long L = 1e6;
|
|
|
+ double T = -omp_get_wtime();
|
|
|
+ for (long i = 0; i < L; i++)
|
|
|
+ GEMM_ker_naive<M,N,K>(C, A, B);
|
|
|
+ T += omp_get_wtime();
|
|
|
+ std::cout<<"FLOP rate = "<<
|
|
|
+ 2*M*N*K*L/T/1e9 << "GFLOP/s\n";
|
|
|
+
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+ \onslide<3-4>%<<<
|
|
|
+ \begin{minted}[
|
|
|
+ frame=lines,
|
|
|
+ fontsize=\scriptsize,
|
|
|
+ linenos,
|
|
|
+ gobble=8,
|
|
|
+ mathescape
|
|
|
+ ]{C++}
|
|
|
+ template <int M, int N, int K>
|
|
|
+ void GEMM_ker_vec(double* C, double* A, double* B) {
|
|
|
+ using Vec = sctl::Vec<double,M>;
|
|
|
+
|
|
|
+ Vec Cv[N];
|
|
|
+ for (int j = 0; j < N; j++)
|
|
|
+ Cv[j] = Vec::Load(C+j*M);
|
|
|
+
|
|
|
+ for (int k = 0; k < K; k++) {
|
|
|
+ const Vec Av = Vec::Load(A+k*M);
|
|
|
+ double* B_ = B + k;
|
|
|
+ for (int j = 0; j < N; j++) {
|
|
|
+ Cv[j] = Av * B_[K*j] + Cv[j];
|
|
|
+ }
|
|
|
+ }
|
|
|
+
|
|
|
+ for (int j = 0; j < N; j++)
|
|
|
+ Cv[j].Store(C+j*M);
|
|
|
+ }
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+ \onslide<5-6>%<<<
|
|
|
+ \begin{minted}[
|
|
|
+ frame=lines,
|
|
|
+ fontsize=\scriptsize,
|
|
|
+ linenos,
|
|
|
+ gobble=8,
|
|
|
+ mathescape
|
|
|
+ ]{C++}
|
|
|
+ template <int M, int N, int K>
|
|
|
+ void GEMM_ker_vec_unrolled(double* C, double* A, double* B) {
|
|
|
+ using Vec = sctl::Vec<double,M>;
|
|
|
+
|
|
|
+ Vec Cv[N];
|
|
|
+ #pragma GCC unroll (8)
|
|
|
+ for (int j = 0; j < N; j++)
|
|
|
+ Cv[j] = Vec::Load(C+j*M);
|
|
|
+
|
|
|
+ #pragma GCC unroll (8)
|
|
|
+ for (int k = 0; k < K; k++) {
|
|
|
+ const Vec Av = Vec::Load(A+k*M);
|
|
|
+ double* B_ = B + k;
|
|
|
+ #pragma GCC unroll (8)
|
|
|
+ for (int j = 0; j < N; j++) {
|
|
|
+ Cv[j] = Av * B_[j*K] + Cv[j];
|
|
|
+ }
|
|
|
+ }
|
|
|
+
|
|
|
+ #pragma GCC unroll (8)
|
|
|
+ for (int j = 0; j < N; j++)
|
|
|
+ Cv[j].Store(C+j*M);
|
|
|
+ }
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+ \end{overprint}
|
|
|
+
|
|
|
+ \column{0.05\textwidth}
|
|
|
+ \column{0.4\textwidth}
|
|
|
+
|
|
|
+ \begin{overprint}
|
|
|
+ \onslide<2-3>%<<<
|
|
|
+ \begin{minted}[gobble=8,fontsize=\footnotesize]{text}
|
|
|
+ M = N = K = 8
|
|
|
+
|
|
|
+ GEMM (naive):
|
|
|
+ FLOP rate = 5.99578 GFLOP/s
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+ \onslide<4-5>%<<<
|
|
|
+ \begin{minted}[gobble=8,fontsize=\footnotesize]{text}
|
|
|
+ M = N = K = 8
|
|
|
+
|
|
|
+ GEMM (naive):
|
|
|
+ FLOP rate = 5.99578 GFLOP/s
|
|
|
+
|
|
|
+
|
|
|
+ GEMM (vectorized):
|
|
|
+ FLOP rate = 29.3319 GFLOP/s
|
|
|
+ \end{minted}
|
|
|
+ %>>>
|
|
|
+ \onslide<6>%<<<
|
|
|
+ \begin{minted}[gobble=8,fontsize=\footnotesize]{text}
|
|
|
+ M = N = K = 8
|
|
|
+
|
|
|
+ GEMM (naive):
|
|
|
+ FLOP rate = 5.99578 GFLOP/s
|
|
|
+
|
|
|
+
|
|
|
+ GEMM (vectorized):
|
|
|
+ FLOP rate = 29.3319 GFLOP/s
|
|
|
+
|
|
|
+
|
|
|
+ GEMM (vectorized & unrolled):
|
|
|
+ FLOP rate = 38.5658 GFLOP/s
|
|
|
+
|
|
|
+ \end{minted}
|
|
|
+ \textcolor{red}{\qquad 36.5\% of peak}
|
|
|
+ %>>>
|
|
|
+ \end{overprint}
|
|
|
+
|
|
|
+ \end{columns}
|
|
|
+
|
|
|
+ % start with triple loop
|
|
|
+ % compiler options
|
|
|
+ % loop unrolling
|
|
|
+ % __restrict__
|
|
|
+ %
|
|
|
+\end{frame}
|
|
|
+%>>>
|
|
|
+
|
|
|
+
|
|
|
+\begin{frame}[t,fragile] \frametitle{GEMM micro-kernel}{} %<<<
|
|
|
+
|
|
|
+ \vspace{-1em}
|
|
|
+ \begin{columns}[t]
|
|
|
+ \column{0.55\textwidth}
|
|
|
+
|
|
|
+ \center
|
|
|
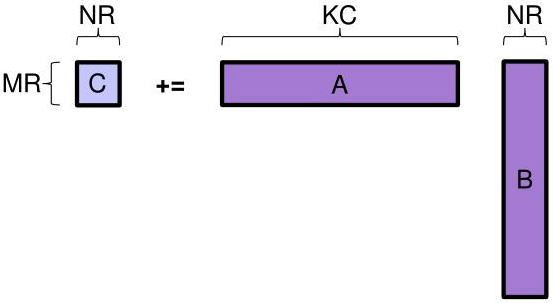
+ \includegraphics[width=0.99\textwidth]{figs/blis-micro-kernel}
|
|
|
+
|
|
|
+ {\scriptsize Source: BLIS framework [Van Zee and van de Geijn 2015]}
|
|
|
+
|
|
|
+ \column{0.05\textwidth}
|
|
|
+ \column{0.4\textwidth}
|
|
|
+
|
|
|
+ \begin{overprint}
|
|
|
+ \onslide<1>%<<<
|
|
|
+ \begin{minted}[gobble=8,fontsize=\footnotesize]{text}
|
|
|
+ M = 8, N = 10, K = 40
|
|
|
+ \end{minted}
|
|
|
+ \textcolor{red}{\qquad 71\% of peak!}
|
|
|
+ %>>>
|
|
|
+ \onslide<2>%<<<
|
|
|
+ \begin{minted}[gobble=8,fontsize=\footnotesize]{text}
|
|
|
+ M = 8, N = 10, K = 48
|
|
|
+
|
|
|
+ GEMM (naive):
|
|
|
+ FLOP rate = 7.9677 GFLOP/s
|
|
|
+
|
|
|
+
|
|
|
+ GEMM (vectorized):
|
|
|
+ FLOP rate = 65.8419 GFLOP/s
|
|
|
+
|
|
|
+
|
|
|
+ GEMM (vectorized & unrolled):
|
|
|
+ FLOP rate = 74.9756 GFLOP/s
|
|
|
+
|
|
|
+ \end{minted}
|
|
|
+ \textcolor{red}{\qquad 71\% of peak!}
|
|
|
+ %>>>
|
|
|
+ \end{overprint}
|
|
|
+
|
|
|
+ \end{columns}
|
|
|
|
|
|
% start with triple loop
|
|
|
% compiler options
|
|
|
@@ -1120,9 +1320,20 @@
|
|
|
|
|
|
\begin{frame} \frametitle{Instruction-level parallelism -- summary}{} %<<<
|
|
|
|
|
|
+ \begin{itemize}
|
|
|
+ \item ..
|
|
|
+ \end{itemize}
|
|
|
+
|
|
|
+ Resources
|
|
|
+ %\begin{itemize}
|
|
|
+ % \item Agner Fog: optimization guide
|
|
|
+ % \item Intel optimization guide
|
|
|
+ %\end{itemize}
|
|
|
+
|
|
|
% Use fast operations instead of slow
|
|
|
% Cast all computations in additions, multiplications, bitwise ops (eg. baobzi)
|
|
|
% Avoid expensive ops (div), branches
|
|
|
+ % Branches hurt performance significantly
|
|
|
|
|
|
|
|
|
% vectorization
|

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}